When building microservices, it’s always a good idea to build in some capability to circuit break on your downstream dependencies whenever they are experiencing issues, or perhaps networking problems that cause delayed response times.
One utility that is fairly common is Hystrix, built by Netflix. This post is not going to detail how to use it, nor how to configure it. However, recently we’ve found what seemed like some interesting behaviour where our http requests were taking longer than we expected for calls that were failing on our downstreams.
This post is an attempt to explain how you should write your HystrixCommands, and in particular, your fallback methods, and why you should care.
TL;DR
When creating HystrixCommands, wrapping your fallbacks in another HystrixCommand isn’t a silver bullet.
Example code can be found on GitHub.
If you’re running IntelliJ IDEA, I’d recommend the GrepConsole plugin if you haven’t already installed it. It’ll make correlating the log output and the diagram a little easier. Further details are in the README.
Setting the scene:
We noticed unexpectedly longer response times from our microservice whenever our downstreams were failing due to slow network traffic. In the case of any failures, we’d written our HystrixCommand’s to look up a previously stored backups from the database. Upon inspection, we found that the fallback method in our HystrixCommand’s were just making direct database calls via our DAO (and subsequently through the driver). And as it turns out, doing so presents two major problems:
1. Indeterministic execution time in the fallback
Once the fallback method is executed, it will not be managed by a timer (however it could very well execute on a timer thread), and subsequently it can affect the response times for the initiating caller. i.e. fallbacks are not bound to be interrupted like in the run() method. Wrapping the fallback call in a HystrixCommand seemed for us, like the right thing to do, but from our testing, this isn’t necessarily the case. More on this later…
2. Slower and slower calls when timing out.
When the fallback is executed because of a timeout, the fallback will be executed on a HystrixTimer thread. A little gotcha is that there are only as many HystrixTimer threads as there are CPU cores. So on a CPU with 4 cores, you’ll only have 4 HystrixTimer threads to execute fallbacks in the event of timeouts. I stress the timeouts because in other circumstances, the fallback will either execute on the initiating thread, or on the Hystrix worker thread, which both have a configurable thread pool – but your timer threads are not! So, if your timer thread is responsible for executing your fallback, and it becomes held up with lengthy executions, then it’s unable to service any other timeouts. This is of course will only really become apparent when you have many concurrent requests, with many downstream failures. You might be thinking this isn’t a great problem, because surely the circuit breaker will kick in and then all fallbacks will execute on the initiating thread, so its only an edge case? You’d be correct, but think about the fact where you might have many downstreams, all of which are timing out because of slow network issues, then this problem becomes compounded until your circuit breakers are enforced!
Below is my attempt at trying to articulate the threads that your command is executed on in particular circumstances.
Green = Initiating thread
Red = HystrixTimer thread
Blue = Hystrix worker thread
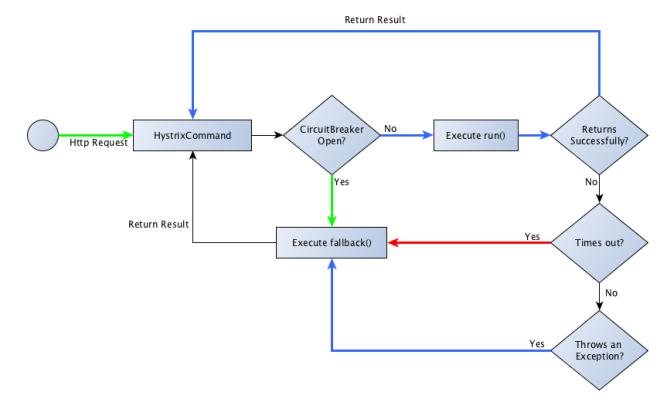
Now I’d like to revisit the comment I made earlier about our assumption that wrapping the fallback into a HystrixCommand call would solve our problems. Unfortunately, it doesn’t really. In fact, I think judging by the sample tests, it probably makes things a little worse! As you’ll see, there are many cases where the result returned to the client was:
Should have timed out by this point!
The reason we get this as the return result is because the HystrixTimer thread never got around to interrupting the running execution because it was held up by other tasks.
The conclusion
I think by now, it’s become pretty clear that when your fallback executes, it should do so as quickly as possible – so that it can release the HystrixTimer thread to do its stuff. One pitfall is to assume that wrapping the fallback in a HystrixCommand would save the day, but in reality, it actually uses up two timer threads which will block until the call stack unrolls.
There is however another interesting alternative to avoid the HystrixTimer thread from being blocked. This is where Lambdas come to the rescue – well, partially at least. If you look at the SlowRunAndFallbackExecutedOnCallingThreadCommand you’ll notice that instead of it returning the standard String type like the other commands, it’s instead returning a Result<String> which is how we’re going to leverage the deferred fallback behaviour. By returning a Result<T> object we’re standardising the response we get whether it was from the run() or the fallback() method. In the fallback, we create a DeferredResult<String> (a specialisation on Result<T>) object which is created with a Java 8 Supplier lambda, and this Supplier forms the unit of work which needs to complete, and will only be invoked when the result is actually needed, which in this example, is when we’re back on the initiating thread, and out of the Hystrix “world” of threads.
The downside of course is that if your fallback is a long blocking call, there is no alternative way for you to deterministically time it out other than doing that yourself inside either the DeferredResult object, or wrapping the DeferredResult<String>.get() method yourself in something like a Future which could then be timed out. Both of which aren’t the most elegant IMHO. So this isn’t the silver bullet to the problem, but it certainly avoids the tying up of the HystrixTimer threads, and bring the control back onto your initiating thread.
Don’t fall into the trap of thinking you can do something like xxx.queue().get(1, TimeUnit.SECONDS), for example, as all that will do is duplicate the work that the HystrixTimer thread is effectively going to do anyway, the only difference is that you’re being more specific, and it still will have no effect on the time taken in the fallback!
I certainly cannot take the credit for this approach. In fact, this solution had never really occurred to me until it was mentioned to me by a rather smart Paul McGuire. I think this is a pretty neat solution – but go check it out for yourself!
Hopefully this has gone a little way to shedding some light on how Hystrix chooses to execute commands on what threads, as I couldn’t find any mention of this sort of behaviour in the docs. I’ll certainly be more thoughtful of the next HystrixCommands I write to take this sort of behaviour into account.

